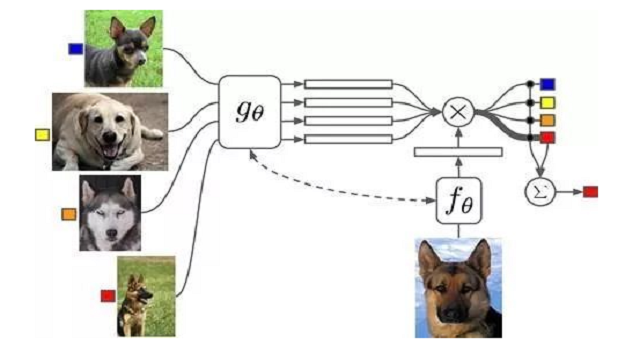
2018-2019最具成长性AI技术Top10–元学习Meta Learning(9/10)
元学习是指将神经网络与人类注意机制相结合,构建通用算法模型使机器智能具备快速自主学习能力的技术。该技术能够使机器智能真正实现自主编程,显著提升现有算法模型的效率与准确性,未来的进一步应用将成为促使人工智能从专用阶段迈向通用阶段的关键。
Meta Learning(元学习)或者叫做 Learning to Learn(学会学习)已经成为继Reinforcement Learning(增强学习)之后又一个重要的研究分支(以后仅称为Meta Learning)。对于人工智能的理论研究,呈现出了
Artificial Intelligence –> Machine Learning –> Deep Learning –> Deep Reinforcement Learning –> Deep Meta Learning
这样的趋势。
之所以会这样发展完全取决于当前人工智能的发展。在Machine Learning时代,复杂一点的分类问题效果就不好了,Deep Learning深度学习的出现基本上解决了一对一映射的问题,比如说图像分类,一个输入对一个输出,因此出现了AlexNet这样的里程碑式的成果。但如果输出对下一个输入还有影响呢?也就是sequential decision making的问题,单一的深度学习就解决不了了,这个时候Reinforcement Learning增强学习就出来了,Deep Learning + Reinforcement Learning = Deep Reinforcement Learning深度增强学习。有了深度增强学习,序列决策初步取得成效,因此,出现了AlphaGo这样的里程碑式的成果。但是,新的问题又出来了,深度增强学习太依赖于巨量的训练,并且需要精确的Reward,对于现实世界的很多问题,比如机器人学习,没有好的reward,也没办法无限量训练,怎么办?这就需要能够快速学习。而人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分的利用以往的知识经验来指导新任务的学习,因此Meta Learning成为新的攻克的方向。
与此同时,星际2 DeepMind使用现有深度增强学习算法失效说明了目前的深度增强学习算法很难应对过于复杂的动作空间的情况,特别是需要真正意义的战略战术思考的问题。这引到了通用人工智能中极其核心的一个问题,就是要让人工智能自己学会思考,学会推理。AlphaGo在我看来在棋盘特征输入到神经网络的过程中完成了思考,但是围棋的动作空间毕竟非常有限,也就是几百个选择,这和星际2几乎无穷的选择对比就差太多了(按屏幕分辨率*鼠标加键盘的按键 = 1920*1080*10 约等于20,000,000种选择)。然而在如此巨量选择的情况下,人类依然没问题,关键是人类通过确定的战略战术大幅度降低了选择范围(比如当前目标就是造人,挖矿)因此如何使人工智能能够学会思考,构造战术非常关键。这个问题甚至比快速学习还要困难,但是Meta Learning因为具备学会学习的能力,或许也可以学会思考。因此,Meta Learning依然是学会思考这种高难度问题的潜在解决方法之一。
来源:互联网